Knowledge layer
Turn the mirror into a queryable graph with search, a wiki, and connectors, then serve it to your editor over MCP.

An optional subsystem (contextlake.kb) turns your mirrored repositories into a
queryable knowledge graph and serves it to AI agents over MCP, so an
assistant can ask "where is X defined?", "who calls Y?", or "which repos
depend on package Z?" instead of grepping hundreds of repos. It's generic: it
indexes any repositories and connects to any configured knowledge sources; no
organization-specific data lives in the package (your sites, keys, and rules go in
a private config file).
Setup#
Install the extra (requires Python ≥ 3.10):
pip install "contextlake[kb]" # knowledge layer (parse + graph + serve)
# ...or get everything for local semantic search in one step (no Ollama / API key):
pip install "contextlake[kb-full]" # = kb + built-in CPU embedder + sqlite-vec ANN
contextlake doctor # check the environment
contextlake index --source ./my-repo # index one repository
contextlake index --workspace ~/work # index every git repo (incremental; --force to rebuild)
contextlake connect --workspace ~/work # link repos to their issues/docs (see below)
contextlake embed # build semantic vectors (optional, see below)
contextlake lint # graph health: stale repos + dangling edges
contextlake wiki # LLM-synthesized, council-verified wiki pages (optional)
contextlake steer # write per-tool steering: AGENTS.md, .mcp.json, …
contextlake query "OrderService" # cited search across the index
contextlake graph --overview --open # visualize the graph (HTML/dot/mermaid/json; offline)
contextlake serve # expose the graph over MCP (stdio or --transport http)
Indexing#
Incremental & time-travel#
index --workspace is incremental, it re-indexes only repos whose git HEAD
moved since their last index, so a scheduled (cron) run stays cheap; pass --force
to rebuild everything, or --watch [--interval N] to keep re-indexing in a loop.
Every indexed snapshot is kept, so query "<text>" --repo R --as-of <commit> does
time-travel, it searches repo R as it was at a previously-indexed commit.
Parallelism & noise-pruning#
Repositories are parsed across worker
processes (CPU-bound work) while the SQLite store is written serially from the
parent, the spawn start method is used on every platform, so behaviour is
identical on Linux, macOS and Windows, with an automatic serial fallback if a
worker pool can't start. It defaults to cpu_count - 1 workers (capped at 8);
set [kb] index_workers to tune it (1 forces serial). The parser also skips
machine-generated/derived files (*.designer.cs, *.min.js, AssemblyInfo.cs,
@generated/<auto-generated> headers) and code files larger than
[kb] max_file_bytes (5 MB), derived graph noise, not real sources, reporting
what it skipped (no silent gaps). Set [kb] skip_generated = false or raise
max_file_bytes to index them anyway.
To exclude your own paths, drop a .contextlakeignore at a repo's root: one
glob per line (# comments and blank lines ignored), matched against each file's
path relative to the repo and its name, so *.lock ignores by name anywhere and
vendor/ ignores a directory and everything under it. It's a small, dependency-free
subset of gitignore syntax (no negation, **, or anchoring), enough to drop
vendored trees and lockfiles from the graph.
Health & maintenance#
contextlake doctor is a quick environment check, SQLite
FTS5, git/glab on PATH, the store's reachability and counts, and the embeddings
status, and exits non-zero if something's wrong. contextlake lint audits the graph
itself, reporting stale repos (HEAD moved since they were indexed, so the index is
behind) and dangling edges (an edge whose endpoint node is missing); it exits
non-zero when it finds problems, so it's CI-friendly.
One-command setup#

Rather than running the steps by hand, bootstrap
chains them, mirror repos → index → connect → embed → wiki → write editor steering,
skipping anything not enabled, so a teammate goes from nothing to a fully-wired
workspace in one step:
contextlake bootstrap --kb-config ~/.contextlake/kb.toml
Skip stages with --no-sync / --no-embed / --no-wiki / --no-connect. For an
isolated CLI, install with pipx install "git+https://github.com/sayak-sarkar/contextlake"
(add the [kb] extra for the knowledge layer), or run ad-hoc with uvx.
Keep it fresh on a schedule#
bootstrap is incremental and branch-safe, so it's
safe to run repeatedly, it re-mirrors, re-indexes only the repos whose HEAD moved,
refreshes the knowledge layer, and rewrites the steering, without touching an
in-progress working tree. Run it from cron:
*/30 * * * * contextlake bootstrap --config ~/.contextlake.ini --kb-config ~/.contextlake/kb.toml >> ~/.contextlake/refresh.log 2>&1
or as a systemd user timer, see examples/contextlake.service
and examples/contextlake.timer.
Code indexing#
Code indexing uses tree-sitter to extract files, classes, functions/methods,
interfaces, imports, and an intra-repo call graph from Python, JavaScript,
TypeScript/TSX, and C# (the parser registry is pluggable). It also reads
manifests (pyproject.toml, package.json, *.csproj) to build a cross-repo
dependency graph through shared package nodes. Agents traverse all of this over MCP,
from finding a definition to cross-repo blast_radius ("what could break if I change
this"), see the full tool list under Serve.
Connectors#
connect enriches the graph with external context. The
Atlassian connector links each repo to the Jira issues and Confluence pages it
references, issue keys harvested from branch/commit names are confirmed against
the live tracker (a single batched JQL call per site prunes false-positives and
fetches each issue's summary/status), and Atlassian URLs found in docs are
classified into issue/page links. It talks to one or more Atlassian sites over
MCP, each independently authenticated. The Figma connector links repos to the
design files they reference, classifying figma.com URLs to a stable file key. The
GitLab connector links each repo to its open merge requests and issues (read
through your authenticated glab). Connectors share one seam, so adding another is a
small, self-contained module; output lands in an isolated graph partition, so
re-indexing a repo's code never disturbs its external links.
Configure it by copying examples/kb.toml.example to
~/.contextlake/kb.toml. Every fact is provenance-stamped (source file + verified
date) and confidence-tagged (EXTRACTED for AST facts, INFERRED for resolved
calls/links, AMBIGUOUS for unconfirmed candidates), and all output is sanitized
before it reaches an agent.
Semantic search#
Semantic search (optional) adds natural-language retrieval on top of the graph.
Enable [embeddings] in the config (local-first, vectors come from an Ollama model
by default, so code never leaves the machine), run contextlake embed to vectorize
the indexed nodes into a local store, and serve then exposes two tools:
semantic_search for queries where the exact symbol name is unknown, and
hybrid_search, which seeds Personalized PageRank with the embedding hits and
propagates relevance across the graph (HippoRAG-style) to surface structurally
related nodes, a function's callers, a package's dependents, that a pure semantic
match would miss. The vector store uses an exact pure-Python cosine scan by default;
install the optional ANN backend with pip install "contextlake[kb-vec]" (sqlite-vec)
for larger workspaces.
Like index, embed is incremental: it re-embeds only repos whose indexed HEAD
moved since they were last embedded, so a scheduled refresh over a large fleet stays
cheap. Pass --force to re-embed everything.
Measuring retrieval quality#
contextlake eval keeps all this falsifiable. Point
it at a golden-query JSON file (--golden, e.g. examples/fixtures/golden-queries.json)
and it reports precision@k / recall@k / MRR plus a cost dimension, estimated
tokens per query and precision per 1k tokens, so "route to the cheapest sufficient
source" is a number, not a vibe. Score any retriever with --retriever fts|semantic|hybrid
(semantic/hybrid need embeddings built); a change like embed-bodies or a reranker is then
judged by whether the numbers move.
Curated wiki#
The wiki (optional, local-first) turns the graph into prose. Enable
[llm] in the config (generation runs on a local Ollama model by default, prompts
never leave the machine) and run contextlake wiki: for each repo it synthesizes a
Markdown page grounded strictly in graph facts (top symbols, dependencies, files)
with a provenance footer citing the commit and sources, then puts the draft through
a verification council, reviewers score it for accuracy, completeness, and
clarity and a chairman publishes only pages above a configurable threshold. Nothing
that fails review is written.
Model providers#
Both the embeddings and wiki tiers are pluggable and take a
provider, defaulting to "auto":
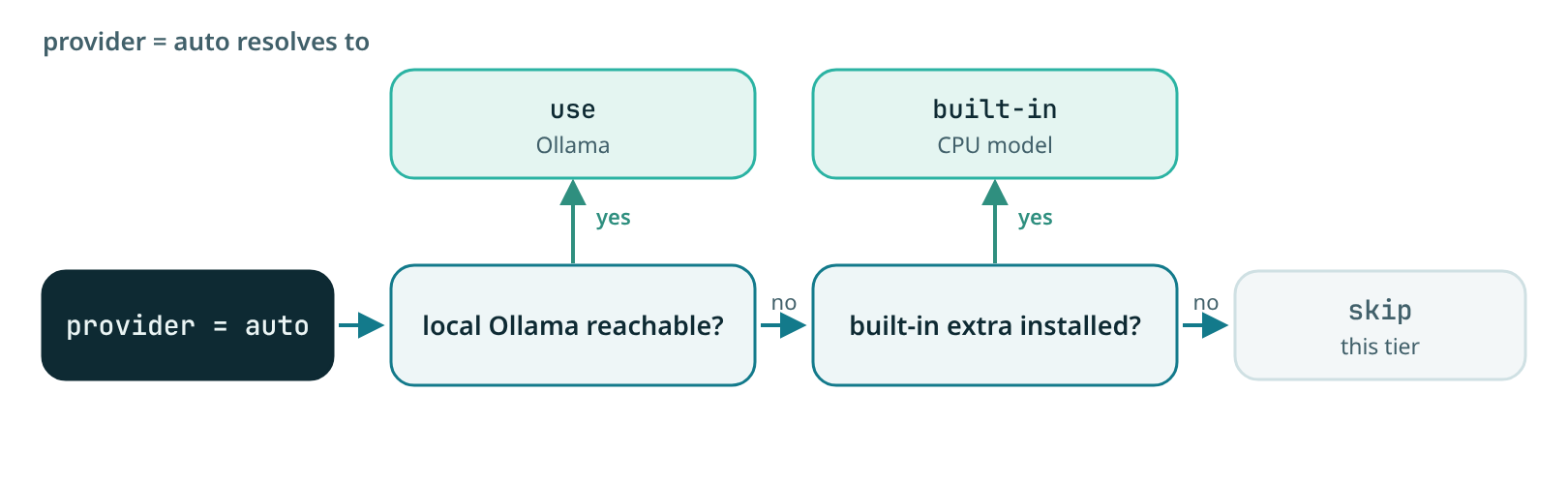
auto(default), resolves to a reachable local Ollama, else the built-in CPU model if its extra is installed, else it skips that tier. So the semantic/wiki tiers Just Work the moment you setenabled = true, with no daemon and no API key.builtin, a small model that runs in-process on CPU and auto-downloads once tocache_dir(default~/.contextlake/models):- Embeddings,
engine = "model2vec"(default): staticpotion-base-8M(~30MB, MIT), numpy inference, very fast at scale,pip install "contextlake[kb-local]". Orengine = "fastembed": ONNXbge-small(~90MB, MIT, higher quality),pip install "contextlake[kb-fastembed]". - Wiki LLM, a
Qwen2.5-0.5B-InstructGGUF (Apache-2.0) viallama-cpp-python,pip install "contextlake[llm-local]". CPU generation is slow and the wiki makes ~4 calls per repo, so prefer Ollama / an API / the Docker image for large workspaces. ollama, a local Ollama daemon (base_url).openai, any OpenAI-compatible API (a hosted key, or a local server like LM Studio, Jan, llama.cpp, vLLM). The key is read from the env var named byapi_key_env(defaultOPENAI_API_KEY), never stored in config.
Notes: behind a TLS-inspecting corporate proxy the first built-in download needs
your OS CA bundle (export REQUESTS_CA_BUNDLE / SSL_CERT_FILE; see
docs/releasing.md). Don't switch the embedder model/dimension against an existing
vector store without re-embedding from scratch, a guard refuses the mismatch. The
prebuilt Docker image (ghcr.io/sayak-sarkar/contextlake) bundles these models so
nothing downloads at runtime. See examples/kb.toml.example.
Visualizing the graph#
contextlake graph draws a bounded slice of the graph, the whole thing
(hundreds of thousands of nodes) is far too large to render, so every view is
scoped from a seed and capped:
contextlake graph --overview --open # repos-as-nodes: the architecture map
contextlake graph --name OrderService --kind class # a symbol's neighbourhood (default 2 hops)
contextlake graph --node <id> --hops 3 # expand around an exact node id
contextlake graph --search "payment" --open # seed from a full-text search
contextlake graph --repo team/service-api # one repo's internal code graph
Seed with one of --node / --name (+--kind) / --search / --repo /
--overview. Bound the result with --hops (default 2), --max-nodes (500),
--max-fanout (50, a per-node cap that stops hub nodes from exploding),
--relation, and --direction {in,out,both}, whatever is dropped is logged,
never silently truncated.
Output is chosen with --format:
html(default), a single self-contained, offline page (cytoscape.js is inlined, so it opens fromfile://with no network, handy air-gapped / behind a proxy). Nodes are coloured by kind and sized by degree; edges are styled by relation/confidence with their labels hidden until you click a node (so the view stays readable). Pan, zoom, drag, and a layout switcher (cose,concentric,breadthfirst,circle,grid) in the page, set the initial one with--layout.--openlaunches the browser;--cdnproduces a small online-only file instead.dot, Graphviz (contextlake graph … --format dot | dot -Tsvg > g.svg).mermaid, pastes into Markdown / GitHub.json, the raw{nodes, edges, meta}for Gephi / cytoscape / custom tooling.
For interactive exploration of a large graph, contextlake graph --serve runs a
local web UI where clicking a node expands it (fetches its neighbours on
demand) so you can walk the graph without pre-rendering all of it.
Serve it to your editor (MCP)#
contextlake serve is an MCP server, so any MCP client can query the graph, and
most of it needs no model: the graph tools (search_code, find_definition,
find_callers, find_dependents, shortest_path, graph_stats,
repo_dependencies, repo_flow, repo_event_flow, blast_radius, get_wiki, get_readme,
get_repo_brief, list_repos, get_repo_links, graph_health) work on their own;
only semantic_search/hybrid_search need embeddings.
The quickest way is to let the tool wire your editors for you. From your workspace root:
contextlake steer --config ~/.contextlake/kb.toml
This writes workspace-specific AGENTS.md (overview, the knowledge tools, and
guardrails), a thin CLAUDE.md that imports it, .windsurfrules,
.kiro/steering/, and merges a .mcp.json entry, so Claude Code, Windsurf,
Kiro, and other agents pick up the workspace context and the MCP server natively. It
also installs a generic library of agent skills/workflows (.claude/skills/,
.windsurf/workflows/), investigate-root-cause, plan-before-coding,
surgical-change, review-before-landing, ship-safely, use-knowledge-graph, so even a
small-context model has a strong operating playbook. It never corrupts your
existing files: if you already have an AGENTS.md, CLAUDE.md, .windsurfrules,
or .kiro/steering, your content is preserved and a clearly-delimited managed block
is appended (and only that block is refreshed on re-runs); .mcp.json is merged so
your other servers stay; a skill file you wrote with the same name is kept as-is.
Custom layers like .devin/ are left untouched.
To wire Claude Code by hand instead:
claude mcp add contextlake-kb -- contextlake serve --config ~/.contextlake/kb.toml
Windsurf / Devin, add the same server in its MCP config (Cascade's MCP
Servers panel, or ~/.codeium/windsurf/mcp_config.json):
{
"mcpServers": {
"contextlake-kb": {
"command": "contextlake",
"args": ["serve", "--config", "~/.contextlake/kb.toml"]
}
}
}
Once connected, ask the agent things like "where is OrderService defined?", "who
calls charge?", or "which repos depend on shared-core?" and it calls the graph
tools directly, you can even have it draft wiki pages from the graph without the
built-in wiki command.